원문
Ten ways to increase MySQL query speed and decrease running speed - SEO Explorer's Blog
We spent three months tweaking MySQL performance, we are sharing some of our insights, this is a 2000 words article that covers some of them.
seo-explorer.io
이 기사는 MySQL 최적화 시리즈의 두 번째 기사입니다. 이 기사에서는 SELECT 속도를 높이고 쿼리 성능을 향상시키며 MySQL 성능을 향상시키는 방법을 다루겠습니다.
여기서 소개하는 개념 중 일부는 이전 기사와 유사할 수 있으므로 요약하고 다시 설명하지는 않겠습니다. 주요 초점은 MySQL SELECT 쿼리의 성능을 개선하는 데에 있습니다.
이 기사에서는 MySQL 저장 엔진 중 하나인 InnoDB에 대해서만 최적화하는 내용을 다룹니다. 일부 제안 사항은 MyISAM에도 적용될 수 있지만, 이 기사는 mysql 쿼리 속도 개선 팁에 대해 InnoDB 사용을 전제로 합니다. (또한 MariaDB와 Percona Server for MySQL에도 적용되는 데이터베이스입니다. 이러한 데이터베이스를 우리는 자주 사용합니다.)
1. MySQL 서버 데이터베이스에 대한 서버 및 하드웨어 선택
이전 기사(빠른 서버 구입 항목 4~6개)의 이 섹션을 참조하십시오. 빠른 요약은 기계식 하드 드라이브를 사용해서는 안 되며 전용 서버가 클라우드 인스턴스보다 빠르다는 것입니다.
2. Measuring MySQL query performance
MySQL 쿼리 성능 측정
MySQL 성능 측정은 이전 기사에서 다루었습니다. 또 다른 옵션은 MySQL이 각 쿼리를 수행하는 데 보고하는 시간을 확인하는 것입니다(SQL은 표준 쿼리 언어를 의미합니다. 지금까지 명확하지 않았다면요). 그러나 쿼리 캐시에서 결과가 제공되지 않았는지 확인해야 합니다.
측정에 영향을 미칠 수 있는 또 다른 캐싱 관련 "문제"는 OS 캐시입니다. 충분한 메모리가 있으면 MySQL 원시 파일을 캐시하고 측정 결과를 왜곡할 수 있습니다.
3. 인덱스 생성하기
인덱스는 모든 SQL 기반 관계형 데이터베이스의 핵심입니다. 올바른 인덱스를 생성하면 성능이 좋아집니다.
MySQL 전문가라면 이 부분은 건너뛰셔도 됩니다. 인덱스가 무엇이고 어떻게 사용되는지 이미 알고 계실 것이라고 생각합니다.
3-1. 선택 및 전체 테이블 스캔 (느림, 느림, 느림)
인덱스가 필요한 이유를 이해하려면 MySQL이 데이터를 가져오는 방법을 알아야 합니다.
간단한 테이블 스키마가 있다고 가정해봅시다:
CREATE TABLE People (
Name VARCHAR(64),
Age int(3)
)우리는 John의 나이를 얻고 싶으므로 간단한 선택 쿼리를 만듭니다:
Select Age from People where Name='John'이렇게 작은 데이터 양이 있는 한 잘 작동할 수 있지만, 테이블이 커질수록 MySQL 쿼리 속도가 느려집니다.
그 이유는 MySQL이 테이블의 모든 행을 스캔하고 Name을 'John'과 비교해야 하기 때문입니다. 그것을 찾았으면 멈출 것이고, 찾지 못했으면 모든 행을 다 확인할 때까지 계속합니다.
테이블의 모든 행을 확인하는 것을 전체 테이블 스캔이라고 하며 성능이 전혀 없습니다. 1,000,000,000개의 행이 있는 테이블을 상상해보세요 (저희 데이터 스토어에는 그런 것들이 있습니다). 모든 MySQL 쿼리가 데이터 전체를 스캔해야 한다면 굉장히 느릴 것입니다.
예를 들어, 3억 개의 키워드가 있는 테이블이 있다고 가정해봅시다. 디버깅 목적으로 가끔 전체 테이블 스캔을 수행해야 합니다. 데이터를 얻기 위해 약 5분이 걸립니다.
3.2. MySQL 인덱스란 무엇인가요?
인덱스는 데이터를 빠르게 검색할 수 있도록 해주는 것입니다. 폰북의 인덱스와 비슷하게 작동합니다. 이름을 검색하면 해당 이름이 있는 페이지로 안내해줍니다.
MySQL에서는 여러 종류의 인덱스가 있으며 각각의 사용 사례와 성능이 있습니다. 우리가 필요한 것에 맞는 올바른 인덱스를 선택하는 것이 중요합니다.
MySQL 인덱스 유형:
- Primary key(기본 키): 각 테이블은 기본 키를 가져야 합니다 (자신이 무엇을 하는지 알고 있다면 제외). 기본 키는 여러 열을 포함할 수 있으며 데이터가 고유하다는 것을 보장합니다.
- Spatial index(공간 인덱스): 이 인덱스는 기하학적 값에 사용되며 지도 및 GIS 관련 작업에 사용됩니다. 저는 이 분야에서 작업한 적이 없으며 이 인덱스를 사용한 적도 없습니다.
- Unique index(고유 인덱스): 이 인덱스는 기본 키와 마찬가지로 인덱스에 포함된 열들이 고유하다는 것을 보장합니다. 하지만 기본 키와 달리 이 인덱스의 관리는 공간과 메모리를 필요로 합니다. 큰 인덱스의 경우 메모리를 충분히 확보해야 할 수도 있습니다. 한번 16GB 인스턴스를 사용한 적이 있었는데, 인덱스에 2억개의 행이 있었고, 한 테이블에서 다른 테이블로 복사하려고 시도하니 MySQL이 충돌했습니다.
- Regular index(일반 인덱스): 이 인덱스는 동일한 값을 가진 다중 값들을 허용하며 고유 인덱스와 유사하게 관리됩니다.
- Full text index(전체 텍스트 인덱스): 이 인덱스는 문자열 열 내의 하위 문자열을 인덱싱할 수 있습니다. 와일드카드 문자열 검색에 유용합니다.
- Descending indexes(내림차순 인덱스): 이는 일반 인덱스와 동일하지만 정렬 순서가 반대입니다. 이것은 MySQL 8에서 지원되며 새로운 데이터를 먼저 처리하는 데 유용합니다.
하나 이상의 열에 인덱스를 사용해야 할까요?
하나의 인덱스 또는 기본 키를 여러 열에 놓을 수 있습니다. 이렇게 하면 where 절에 많은 행을 넣을 경우 동일한 인덱스를 사용할 수 있습니다.
각각의 행에 별도의 인덱스를 넣는다면 MySQL 실행 계획은 모든 인덱스에서 결과를 찾은 다음 모든 인덱스를 모두 일치하는 것만 찾습니다.
모든 결과를 찾은 다음에 병합하는 것은 자원을 크게 낭비하는 것입니다! 여러 열에 동일한 인덱스를 사용한다면 MySQL 실행 계획은 첫 번째 열에서만 결과를 찾은 다음 두 번째 열의 where 절로 해당 결과를 필터링합니다. 그리고 그 이후로도 계속합니다.
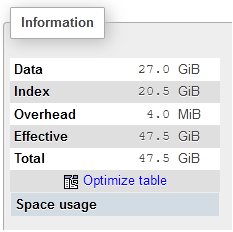
한 열 이상에 인덱스를 넣는 것의 단점은 인덱스 크기입니다. 때로는 인덱스가 상당히 커질 수 있으며, 아래 사진에서 볼 수 있습니다 (phpMyAdmin을 사용하여 촬영).
4. MySQL database table schema DDL
다음 단락에서는 테이블 스키마에 대해 논의할 것이므로, 다음과 같이 테이블 스키마를 설명합니다:
CREATE TABLE Search (
SearchID BigInt,
Keyword Varchar(64),
PRIMARY KEY (SearchID),
INDEX idxKeyword (Keyword)
);
저희 테스트 테이블은 3억 개의 레코드로 채워져 있습니다. (DDL은 데이터 정의 언어를 의미합니다.)
5. Checking how your selects are behaving
인덱스와 기본 키를 추가하는 것은 MySQL이 그것들을 사용한다는 것을 의미하지는 않습니다. MySQL은 주어진 쿼리에 대해 인덱스를 어떻게 사용할지에 대한 고유한 논리를 가지고 있습니다. 느린 쿼리나 여러 번 실행되는 쿼리의 경우, 내부 동작을 확인하는 것이 좋은 관행입니다.
이를 위해 'explain' 명령을 사용합니다. SQL 명령어 앞에 'explain'을 두면 MySQL은 실행 계획을 알려주며, 이를 통해 MySQL 쿼리의 속도에 어떤 영향을 미치는지 확인할 수 있습니다.
5.1. The query execution plan
쿼리 실행 계획(Query Plan)은 데이터베이스의 주요 목표인 데이터를 저장하고 빠르게 검색하는 것을 위해 MySQL이 쿼리를 실행하기 전에 찾아야 하는 것입니다.
쿼리 실행 계획을 찾기 위해 MySQL은 다음을 결정해야 합니다:
- 어떤 인덱스를 사용할 것인지
- 어떤 인덱스의 순서를 사용할 것인지
- 조인을 사용하는 경우, 먼저 어떤 조인을 수행할 것인지
- 등등
우리가 최적화하고자 하는 쿼리에 대해서는 실행 계획(또는 쿼리 계획)을 확인해야 합니다. 그 이유는 우리가 생각하는 방식이 MySQL에게는 올바른 방식이 아닐 수 있기 때문입니다. 또한, 우리의 인덱스가 실행하려는 쿼리에 사용 가능하지 않을 수도 있습니다.
5.2. Explain on a primary key
프라이머리 키에 대한 설명 예시를 드리겠습니다.
예를 들어, 다음과 같은 SQL 문을 설명해봅시다:
explain SELECT * FROM `Search` where SearchID=1;
여기서 SearchID는 프라이머리 키입니다. 우리가 받는 응답은 다음과 같습니다:
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | Search | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 |100.00 | NULL |
+----+-------------+--------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
우리는 확인할 수 있습니다. MySQL은 프라이머리 키를 사용하여 선택하고 하나의 행만 사용합니다.
5.3. Explain without primary key
프라이머리 키가 없는 경우의 설명을 살펴봅시다.
explain SELECT * FROM `Search` as Search where Results=1;
Results 열에는 인덱스나 프라이머리 키가 없으며 결과는 다음과 같습니다:
+----+-------------+--------+------------+------+---------------+------+---------+------+-----------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+-----------+----------+-------------+
| 1 | SIMPLE | Search | NULL | ALL | NULL | NULL | NULL | NULL | 245410801 | 10.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+-----------+----------+-------------+
전체 테이블 스캔(full table scan)을 수행하게 됩니다. 이는 매우 느리게 실행될 것입니다.
5.4 Explain for index
인덱스가 있는 경우의 설명을 살펴봅시다.
explain SELECT * FROM `Search` as Search where Keyword='test';
결과는 다음과 같습니다:
+----+-------------+--------+------------+------+---------------+------------+---------+-------+-------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+-------+----------+-------+
| 1 | SIMPLE | Search | NULL | ref | IdxKeyword | IdxKeyword | 12 | const | 49082 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+------------+---------+-------+-------+----------+-------+
MySQL은 49082개의 행을 처리할 것입니다. 그러나 실제로 얼마나 많은 행이 있는지 확인해봅시다:
SELECT count(*) FROM `Search` as Search where Keyword='test';
결과는 다음과 같습니다:
+----------+
| count(*) |
+----------+
| 26094 |
+----------+
설명에 표시된 것보다 더 적은 행이 있습니다. 이것은 MySQL이 인덱스를 관리하는 방식 때문일 수 있지만 여전히 충분히 빠르며 전체 테이블 스캔이 아닙니다.
6. Checking the where clause for the MySQL query
MySQL 쿼리의 where 절을 확인하는 것은 매우 중요합니다. 왜냐하면 데이터베이스의 목적은 특정 데이터를 빠르게 가져오는 것이기 때문입니다.
따라서 where 절에서 검사하는 열이 인덱싱되어 있거나 작은 크기인지 확인하여 스캔이 빠르게 수행되도록 해야 합니다.
6.1 복잡한 where 절의 MySQL 인덱스 최적화
'explain' 단락은 인덱스가 where 절에 사용된 몇 가지 예제를 다루었습니다. 그러나 이들은 간단한 예제였습니다. 다른 예제를 보여드리겠습니다. 여기서는 프라이머리 키와 인덱스를 모두 사용하는 경우입니다:
explain select * from Search as Search where SearchID between 1 and 1000000 and Keyword between 'aaaaaaaaa' and 'bbbbbbbbb';
결과는 다음과 같습니다:
+----+-------------+--------+------------+-------+--------------------+---------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+--------------------+---------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | Search | NULL | range | PRIMARY,IdxKeyword | PRIMARY | 4 | NULL | 1052210 | 12.30 | Using where |
+----+-------------+--------+------------+-------+--------------------+---------+---------+------+---------+----------+-------------+
MySQL은 두 개의 인덱스를 모두 사용한 것을 볼 수 있습니다.
계산된 열에 대한 인덱스 선택 없이 SQL 예제
이번에는 다음과 같이 해 보겠습니다:
explain select * from Search as Search where MOD(SearchID,2)=1;
이 예제에서는 프라이머리 키 열에 대해 계산을 수행합니다. MySQL이 어떻게 처리하는지 확인해보세요:
+----+-------------+--------+------------+------+---------------+------+---------+------+-----------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+-----------+----------+-------------+
| 1 | SIMPLE | Search | NULL | ALL | NULL | NULL | NULL | NULL | 245412211 | 100.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+-----------+----------+-------------+
프라이머리 키가 있는데도 전체 테이블 스캔을 수행했습니다! 이 문제를 해결하는 방법은 사전 계산 필드를 추가하고, 해당 필드를 인덱싱하여 where 절에서 해당 인덱스 필드를 사용하는 것입니다.
잘못된 유형의 인덱스
인덱스된 열에서 와일드카드(select * from Search as Search where Keyword like '%a%')를 사용하는 경우, MySQL은 다음과 같이 처리합니다:
+----+-------------+--------+------------+------+---------------+------+---------+------+-----------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+-----------+----------+-------------+
| 1 | SIMPLE | Search | NULL | ALL | NULL | NULL | NULL | NULL | 245412257 | 11.11 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+-----------+----------+-------------+
이 경우에는 전체 테이블 스캔이 필요하며, 이러한 경우 'Keyword' 열에 전체 텍스트 인덱스를 추가해야 합니다.
7. Optimize order by and index column selection
주문하기(order by)와 인덱스 열 선택 최적화
우리는 여기서 주문하기(order by)를 사용하여 where 절에 있는 기본 키를 사용합니다:
explain select * from Search where SearchID between 0 and 1000000 order by SearchID;
결과는 다음과 같습니다:
+----+-------------+--------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | search | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1052210 | 100.00 | Using where |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+
MySQL이 기본 키를 사용한 것을 볼 수 있습니다. 이제 인덱스를 정렬 요소로 사용해 보겠습니다:
explain select * from Search where SearchID between 0 and 1000000 order by Keyword;
이번에는 작은 놀라움이 있습니다:
+----+-------------+--------+------------+-------+---------------+---------+---------+------+---------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra
|
+----+-------------+--------+------------+-------+---------------+---------+---------+------+---------+----------+-----------------------------+
| 1 | SIMPLE | search | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1052210 | 100.00 | Using where; Using filesort |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+---------+----------+-----------------------------+
MySQL이 우리의 인덱스를 사용하지 않았습니다. 데이터를 수동으로 정렬하고 있어 MySQL 쿼리 속도가 느려질 수 있습니다.
8. No index on table join queries
테이블 조인 쿼리에서의 인덱스
하나 이상의 테이블을 조인(내부 조인, 왼쪽 조인, 오른쪽 조인 등)할 때, 조인하는 열에 인덱스가 있는지 확인해야 합니다. 그렇지 않으면 MySQL은 적절한 조인을 수행하기 위해 전체 테이블 스캔을 해야 합니다.
이런 경우를 어떻게 알 수 있을까요? EXPLAIN을 사용하세요. 이제 여러분은 이것을 사용하는 전문가일 겁니다. 😊
9. High MySQL performance configuration
높은 MySQL 성능 구성
기본적으로 MySQL 설정은 겸손하게 구성되어 있으며 WordPress와 같은 웹 사이트 작업을 지원하도록 설계되었습니다.
현대적인 데이터베이스에서 기대하는 성능을 얻으려면 기본 설정을 조정해야 합니다.
이러한 설정은 my.cnf 파일에 있습니다. CentOS의 경우 /etc/my.cnf 경로에 있습니다.
10. Tuning tips for your MySQL database
MySQL 데이터베이스를 조정하는 팁
10.1. innodb_buffer_pool_size
개인적으로 이것은 가장 중요한 MySQL 설정이라고 생각하며, 이 설정은 MySQL이 테이블과 인덱스 데이터를 캐시하는 데 사용하는 메모리 양을 설정합니다. 이 설정은 고정된 크기가 아니며, MySQL은 설정된 크기의 10% 더 많은 메모리를 할당할 수도 있습니다.
또한 다른 애플리케이션들이 실행되고 있을 수 있으므로, 그들을 위해 메모리를 예약해야 합니다.
내가 도와준 친구(이전 글에서 언급한 친구)에게서 테이블 구조를 확인하기 전에도 MySQL에 할당된 메모리를 먼저 확인했습니다. 그의 기계에서는 기본 설정이었으며, 2GB였습니다. 이를 48GB로 변경한 결과, 성능이 크게 향상되었습니다.
10.2. innodb-buffer-pool-instances
버퍼 풀이 나눠지는 인스턴스의 수를 의미하며, 이는 스레드와의 더 나은 동시성을 위해 사용됩니다. 버퍼 풀이 1.3GB 이상인 경우에만 적용됩니다.
Windows 32비트에서는 기본값이 버퍼 풀 크기를 128MB로 나눈 것입니다. 다른 모든 시스템에서는 기본값이 8입니다.
새로운 AMD 프로세서에서는 64개 또는 128개의 코어를 가질 수 있으며, 이 값을 실험해보면 더 나은 성능을 얻을 수 있습니다.
10.3. join_buffer_size
이 설정은 조인을 생성하는 동안 사용되는 조인 버퍼에 할당할 메모리 양을 MySQL에 지시합니다.
조인 데이터가 너무 큰 경우, MySQL은 하드 드라이브에 임시 테이블을 사용합니다.
기본값은 256KB이며, 이 값을 높이면 모든 MySQL 스레드의 값을 증가시킬 것입니다.
이 값 또한 비교적 작습니다. 조인은 작아야 하기 때문에 이 값을 높이기 전에 디자인이 올바른지 확인하고, 대신 큰 조인이 있는 쿼리 전에 옵티마이저에게 "힌트"를 줄 수도 있습니다.
이 설정에 대해서는 MySQL 기술 문서를 참조하세요: https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html#sysvar_join_buffer_size
11. MySQL table optimization
MySQL 테이블 최적화
MySQL 테이블은 데이터를 삽입한 후 성능이 저하될 수 있으므로, 테이블을 최적화하는 옵션이 있습니다. 구문은 다음과 같습니다:
Optimize table tablename;
일반적으로 MySQL은 새로운 테이블을 생성하고, 모든 데이터를 새 테이블에 삽입한 후 인덱스를 다시 빌드합니다.
테이블 최적화는 시간이 많이 걸리며, 임시 테이블을 위해 서버에 충분한 공간이 있는지 확인해야 합니다. 공간이 충분하지 않아 데이터베이스 손상이 발생한 적이 한두 차례 있었습니다. 테이블을 최적화한 후에는 더 빠른 MySQL 쿼리 속도와 MySQL 삽입 속도를 기대할 수 있습니다.
테이블 최적화 이후에 데이터를 삽입하지 않는다면, 다시 최적화할 필요가 없습니다.
12. 힌트를 사용한 쿼리 최적화
우리가 데이터에 어떻게 접근하길 원하는지 가장 잘 알기 때문에, 최적화 힌트를 사용하여 쿼리를 사용자 정의할 수 있습니다.
많은 힌트가 있으며, 모두 다루기는 불가능합니다. 모든 힌트를 보려면 여기를 참조하세요: https://dev.mysql.com/doc/refman/8.0/en/optimizer-hints.html
이 문서에서는 사용한 힌트와 경험한 내용을 다루겠습니다.
12.1. Statement Execution Time Optimizer Hints
Statement Execution Time Optimizer Hints를 사용하면 쿼리의 실행 시간을 제한할 수 있습니다. 실행 시간 제한은 일부 쿼리가 너무 오래 걸릴 수 있기 때문에 중요합니다.
예를 들어, 우리의 프로덕션 서버에서는 인덱스를 병합할 때, 결과가 백만 개 이상의 행을 반환합니다.
특정 조건에서 이러한 쿼리는 너무 오래 걸릴 수 있으며, 종료하는 것이 더 나을 수 있습니다. 이를 위해 다음과 같이 할 수 있습니다:
SELECT /*+ MAX_EXECUTION_TIME(1000) */ * from table1000은 밀리초 단위로, 최대 1초까지 허용합니다.
12.2. Variable-Setting Hint Syntax
MySQL 글로벌 변수에 대해 다른 값을 사용하고 싶을 수 있습니다. 예를 들어, 특정 쿼리에 대해 더 큰 정렬 버퍼를 원할 수 있습니다. 이를 다음과 같이 수행할 수 있습니다:
SELECT /*+ SET_VAR(sort_buffer_size = 16M) */ * from table
12.3. SQL_CALC_FOUND_ROWS
이 플래그는 MySQL에게 쿼리에서 반환된 결과 수를 알고 싶다고 알려줍니다. 이렇게 하면 count(*)과 실제 데이터를 위해 두 개의 쿼리를 수행하는 시간을 절약할 수 있습니다(MYSQL 데이터베이스 쿼리 속도를 높일 수 있습니다). 일년 전에 알았으면 좋았을 텐데요.
예를 들어:
Select SQL_CALC_FOUND_ROWS * from table
그런 다음 값을 가져오기 위해 다음과 같이 실행할 수 있습니다:
Select FOUND_ROWS()데이터를 가져올 수 있습니다. 이 값은 limit을 사용했더라도 총 사용 가능한 데이터를 반영합니다.
13. OLTP vs OLAP
OLTP 대 OLAP
데이터베이스 디자인에는 두 가지 설계 패러다임이 있습니다:
- OLTP - 온라인 트랜잭션 처리
- OLAP - 온라인 분석 처리
13.1. OLTP란 무엇인가요?
OLTP는 삽입 및 선택 속도와 신뢰성을 제공하는 것을 목표로 하는 디자인으로, 은행에서 현재 연도의 데이터를 관리하는 데 전형적으로 사용됩니다:
- 고객은 자신의 거래를 볼 수 있습니다.
- 은행은 새로운 레코드를 삽입할 수 있습니다.
- 은행은 기존 레코드를 삭제하거나 수정할 수 있습니다.
OLTP에서 사용되는 일부 디자인 개념:
- 데이터 정규화 - 데이터를 더 작은 테이블로 분할하여 더 작은 데이터 저장소를 사용하고 적은 삽입을 수행할 수 있습니다. 데이터를 쿼리할 때 하나 이상의 조인을 사용합니다.
- 트랜잭션 - 이를 통해 문제가 발생한 경우 롤백이 가능하며 여러 동작을 하나의 원자적인 단위로 유지합니다.
- 기본 키/외래 키 조합을 사용하여 참조 무결성 유지로 데이터의 삽입/삭제 오류를 방지합니다.
13.2. OLAP란 무엇인가요?
OLAP는 선택 작업만 제공하는 디자인으로, 삭제/업데이트/삽입 작업은 없습니다. 은행에서 지난 해의 데이터를 관리하는 데 전형적으로 사용됩니다:
- 고객은 자신의 기록을 볼 수 있습니다.
- 레코드는 더 이상 변경할 수 없습니다. 데이터는 읽기 전용입니다.
OLAP의 일부 디자인 개념:
- 데이터는 정규화되지 않지만 블롭으로 저장되어 하나의 긴 줄로 저장됩니다.
- 디자인 개념은 아니지만 비용을 절약하기 위해 데이터는 대개 기계식 하드 드라이브에 저장되며, 이는 선택 작업에 빠른 디자인이어야 함을 의미합니다.
- 데이터베이스에는 통계 및 기타 정보가 계산되고 빠른 검색을 위해 오프타임에 저장되는 요약 테이블이 포함되어 있습니다.
13.3. 어떤 것을 선택해야 할까요?
올바른 디자인은 데이터베이스를 성공시키거나 망치게 할 수 있습니다. 데이터에는 두 가지 수명 주기가 있을 수도 있습니다. 첫 번째 주기는 OLTP이며, 더 이상 변경할 수 없을 때 OLAP로 전환합니다.
선택 기준은 다음과 같습니다:
- 데이터가 읽기 전용인가요? OLAP를 사용하는 것을 고려하세요.
- 데이터를 읽고 쓰는가요? OLTP를 사용하세요.
- 데이터를 읽기 전용과 읽고 쓸 수 있는 부분으로 분할할 수 있나요? 데이터를 OLTP와 OLAP 저장소로 나누세요.
14. Even more ways to optimize MySQL queries
더 많은 방법으로 MySQL 쿼리 최적화하기
저희는 이 가이드의 두 번째 파트를 작성하여 MySQL 데이터베이스를 더욱 최적화하는 방법과 팁을 제공했습니다. 이곳에서 읽을 수 있습니다: MySQL 쿼리 속도를 높이고 실행 속도를 줄이는 더 많은 방법 (파트 2)
Summary
이 가이드에서는 MySQL 쿼리 속도와 성능을 최적화하는 일부 측면을 다뤘으며, 다음 가이드에서는 테이블 최적화, 메모리 설정 등의 주제를 다룰 예정입니다.
'DB' 카테고리의 다른 글
| 스레드 풀 (Thread Pool) (1) | 2024.09.09 |
|---|---|
| MySQL 엔진의 구성요소 설명 (1) | 2024.09.06 |
| DB 공부 도움글 (0) | 2023.07.29 |
| [번역] 삽입 속도를 높이기 위해 느린 MySQL을 최적화하는 20가지 방법 (0) | 2023.07.26 |
| [번역] 속도와 성능을 위해 MySQL 쿼리를 최적화하는 방법 (0) | 2023.07.23 |